단어의 빈도와 문서의 빈도의 역수를 사용하여 DTM 내의 각 단어들마다 중요한 정도를 가중치로 주는 방법.
> 우선 DTM을 만든 후, TF-IDF 가중치를 부여해야 한다.
TF-IDF 가중치 부여한 결과)
3) 파이썬 코드
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
corpus = [
'you know I want your love',
'I like you',
'what should I do ',
]
① DTM
vector = CountVectorizer() # DTM 벡터화를 위한 객체 생성
x_train_dtm = vector.fit_transform(corpus) # 해당 단어들을 벡터화 진행
print(x_train_dtm.toarray()) # 벡터가 어떻게 생겼는지 확인
② TF-IDF
tfidf_transformer = TfidfTransformer() # tfidf 벡터화를 위한 객체 생성
tfidfv = tfidf_transformer.fit_transform(x_train_dtm) # x_train_dtm에 대해서 벡터화 진행
print(tfidfv.toarray()) # 벡터가 어떻게 생겼는지 확인
4) 번외 - fit_transform 과 transform
fit_transform()
생성한 객체 (vector, tfidf_transformer) 에다가 해당 문서 혹은 단어들의 벡터값을 저장하면서 벡터화를 진행하는 함수.
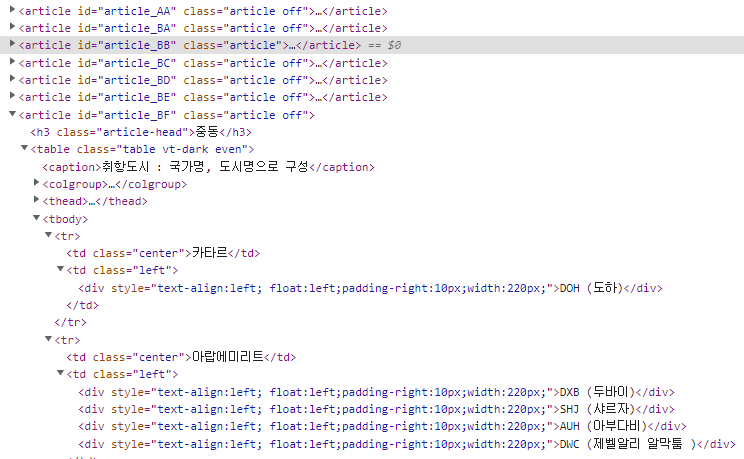
암턴 select든 find든 find_one 혹은 select_one을 사용하지 않으면 해당 id나 class를 가진 값들을 싸그리 다 찾아줘버리는데, 이때 텍스트가 정상적으로 추출되지 못하는 문제가 발생했었다.
텍스트를 추출하지 않은 채 어떤 데이터가 뽑히는지 살펴본 다음,
[] <- 이런 대괄호로 데이터가 묶여있으면 그 안에 있는 텍스트를 인지하지 못한다고 보면 된다.
select로 텍스트 추출이 안되면 find를 사용해보고, find로 안되면 select를 사용해보면.. 될 것 같음...
f = open("icn_arrs.txt", "w+")
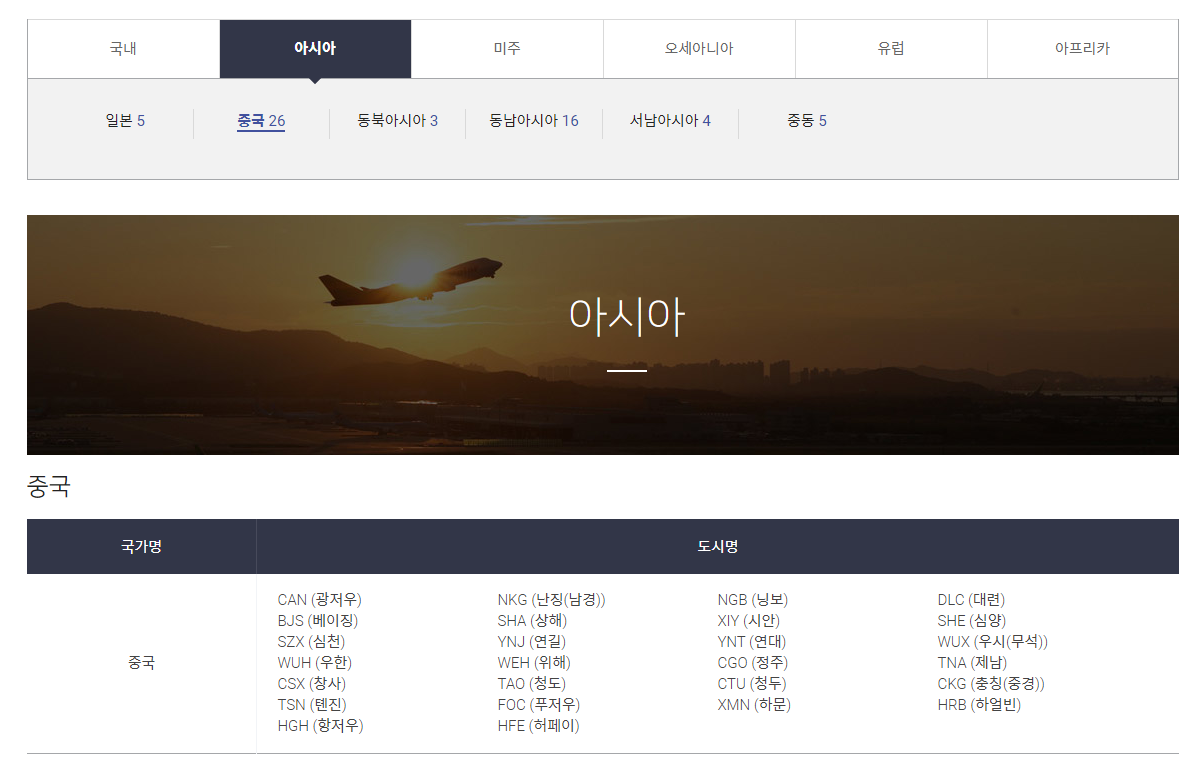
data = requests.get('https://www.airport.kr/ap/ko/dep/serviceCityList.do',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
locals = soup.select("article")
for local in locals:
continent = local.find('h3', class_ = 'article-head').text
countries = local.select('tbody > tr')
for country in countries
countryName = country.find('td', class_ = 'center').text
airports = country.select('div')
for airport in airports:
print(continent, countryName, airport.text, file=f)