통계분석 수업에서 텀 프로젝트를 하고 있는데, '공항 취항지' 정보가 필요했다.
https://www.airport.kr/ap/ko/dep/serviceCityList.do
인천국제공항
www.airport.kr
이렇게 인천국제공항 웹사이트에서 해당 정보를 찾을 수 있었지만 문제는...
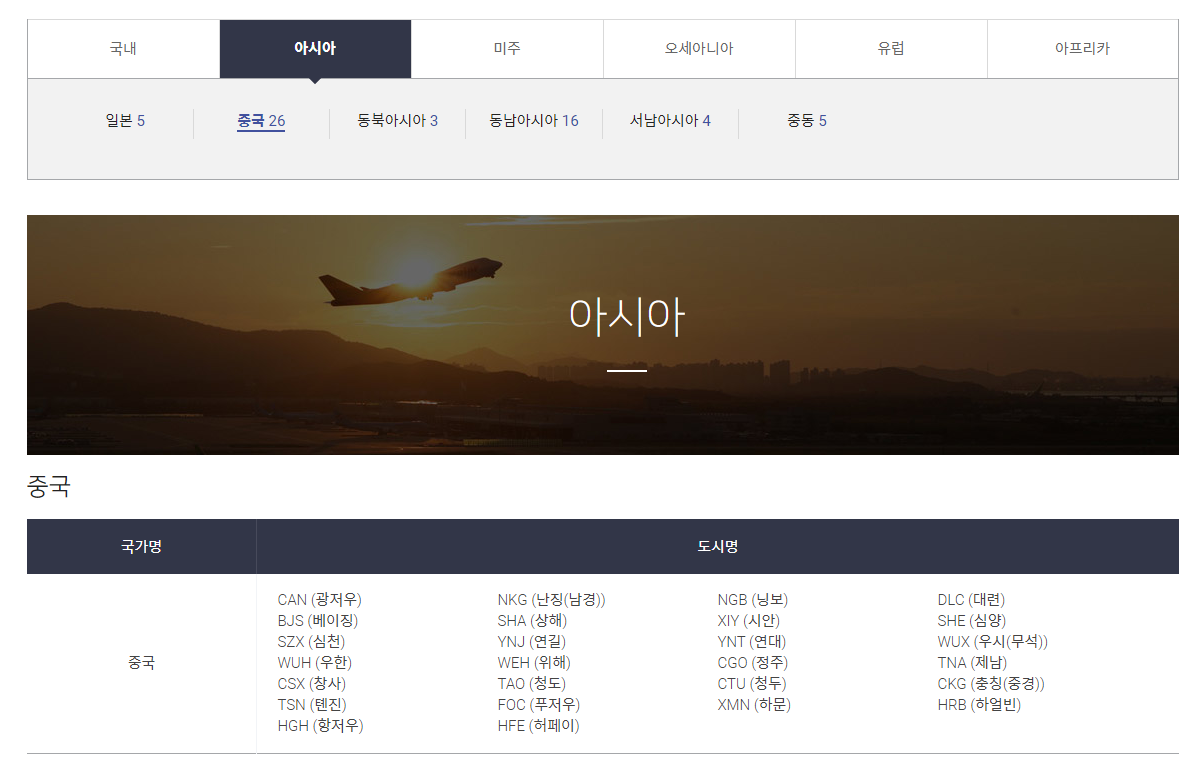
구분이... 1) 대륙 2) 국가 3) 취항지로 되어있었다.
이거 다 긁어오고.. 가공하고... 생각만 해도... ㄱ ㅐ 귀차늠
그때 머릿속에 떠오른 '크롤링'!
결국 공부하는 겸 해서 파이썬 코드를 짜보기로 했다
사실 처음에는 저 탭을 자동으로 눌러가면서 크롤링을 해야하는 줄 알고, 동적 크롤링 라이브러리인 selenium을 사용해보려고 했다.
하지만 배웠던 라이브러리가 아니라 사용하기가 넘 어려웠고 ㅠㅠ
저 웹사이트 코드를 살펴보니
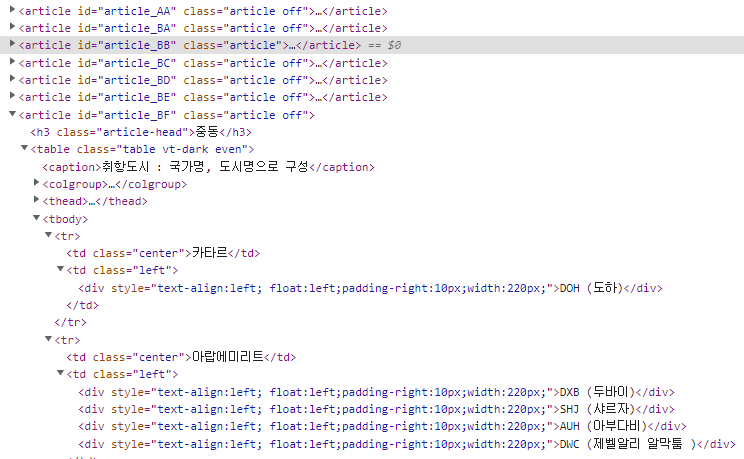
굳이 탭버튼으로 이동을 하지 않아도 되게끔(?) 모든 정보가 걍 싸그리 다 들어있었다.
그래서 그냥 BeautifulSoup으로 크롤링을 하기로 결정 ㅎㅎ
이번에 크롤링 코드를 짜면서 알게된 중요한 점은 find와 select의 차이라고 할 수 있겠다.
내가 원하는 인천공항 취항지 데이터의 구조를 살펴보면,
1) "article"이라는 id를 가지고 각 대륙과 국가의 취항지들이 구분이 되어 있었고
2) 그 안에 "h3" class로 대륙 정보가 있고
3) article > table > tbody > tr안에 "center" class로 국가 정보가 있고
4) "div"로 취항지들 정보가 들어있었다.

그래서 코딩 계획은
1) article들을 빼낸다.
2) h3 class로 대륙 정보를 빼낸다. (for 문 들어가고)
3) td > center class로 국가 정보 빼낸다. (for 문 또 들어가고)
4) div로 취항지 정보 빼낸다.
print()
대충 이 흐름이 맞았는데 가장 큰 문제는 text가 추출되지 않을 때가 있다는 거였다.
주로 attribute error 였는데, 해석해보자면 "text가 없는데 뭘 추출하라는거니??" 일 것이다.=
이 문제는 find와 select를 혼용하면서 해결이 됐다.
추측하기로는, find는 전체 주소 안에서 해당 class나 id를 가지고 있는 값을 "검색해서" 찾아주는 것 같았고,
select는 class나 id 값 등의 "특정 주소값"을 통해서 타고타고~ 값을 찾아주는 것 같았다.
#select
songs = soup.select('#body-content > div.newest-list > div > table > tbody > tr')
#find
continent = local.find('h3', class_ = 'article-head').text
암턴 select든 find든 find_one 혹은 select_one을 사용하지 않으면 해당 id나 class를 가진 값들을 싸그리 다 찾아줘버리는데, 이때 텍스트가 정상적으로 추출되지 못하는 문제가 발생했었다.
텍스트를 추출하지 않은 채 어떤 데이터가 뽑히는지 살펴본 다음,
[] <- 이런 대괄호로 데이터가 묶여있으면 그 안에 있는 텍스트를 인지하지 못한다고 보면 된다.
select로 텍스트 추출이 안되면 find를 사용해보고, find로 안되면 select를 사용해보면.. 될 것 같음...
f = open("icn_arrs.txt", "w+")
data = requests.get('https://www.airport.kr/ap/ko/dep/serviceCityList.do',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
locals = soup.select("article")
for local in locals:
continent = local.find('h3', class_ = 'article-head').text
countries = local.select('tbody > tr')
for country in countries
countryName = country.find('td', class_ = 'center').text
airports = country.select('div')
for airport in airports:
print(continent, countryName, airport.text, file=f)앗 적다보니 class 안의 텍스트는 무조건 find로 추출을 해야하는건가? 싶다..?
아무튼 select로 안되면 find 써보고 find로 안되면 select 써보세요
'Development > Python' 카테고리의 다른 글
| 크롤링 기초 : BeautifulSoup (0) | 2022.07.26 |
|---|---|
| 크롤링 기초: HTML 문서의 구성 (0) | 2022.07.26 |
| class, 객체, try& except, package (0) | 2022.07.26 |
| Network Analysis (1) networkX in Python (0) | 2022.03.17 |