이번 과제는 지니뮤직 사이트의 음원 순위를 크롤링하는거였다.
사실 과제 자체가 많이 어렵진 않았다.
3주차에서 배운 내용들과 추가로 알려주신 function을 이용하면 할 수 있었음.
처음에 썼던 코딩은 이랬다
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://www.genie.co.kr/chart/top200?ditc=M&rtm=N&ymd=20210701',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
songs = soup.select('#body-content > div.newest-list > div > table > tbody > tr')
for song in songs:
a = song.select_one('td.info')
b = song.select_one('td.number')
rank = b.text[0:2].strip()
artist = song.select_one('a.artist.ellipsis').text.strip()
title = song.select_one('a.title.ellipsis').text.strip()
print(rank, title, artist)1. 문제 발견
그런데 이렇게 해보니 문제가 하나 발생했다 ^^
저스틴 비버의 피치쓰... 이눔자식에.... 쓸데없는 친구 하나가 딸려오는 것이었다
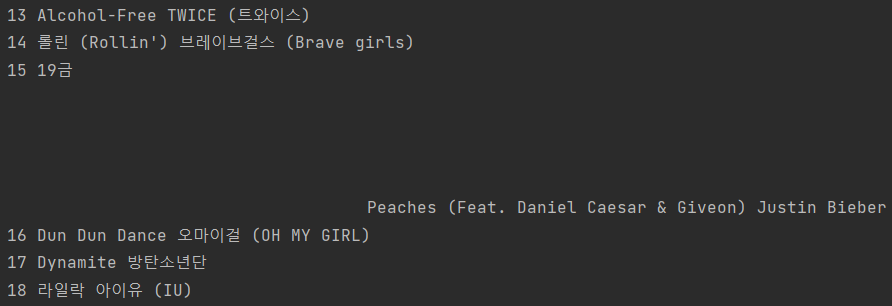
이렇게....
딴건 잘 나오는데 피치쓰...왜이래...?
2. 원인 분석
결과물이 이렇게 나오는 이유는,
크롤링으로 읽어오는 class에
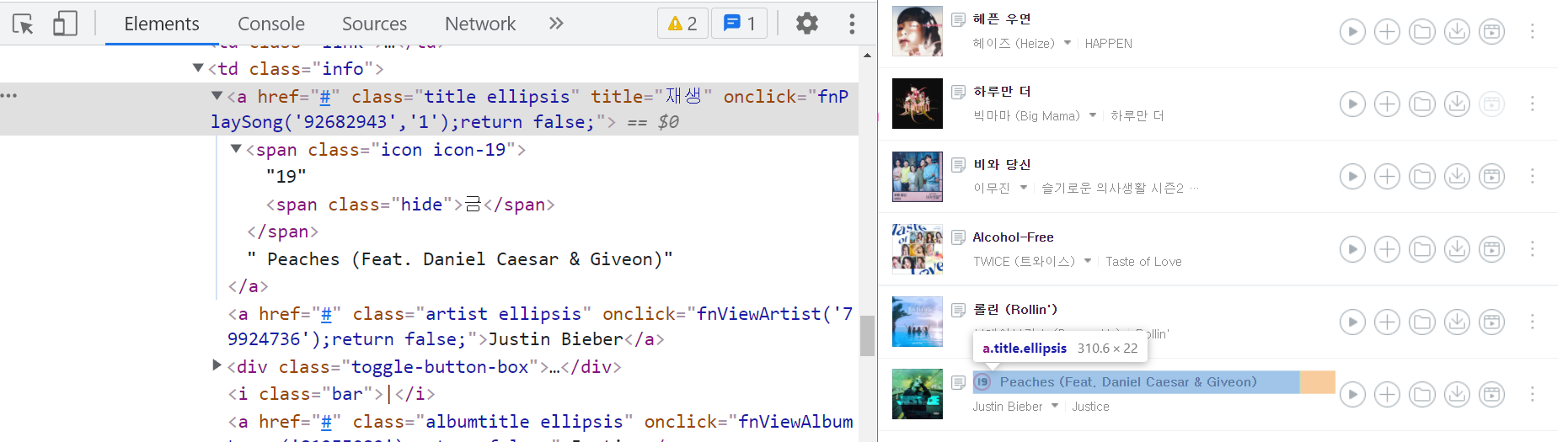
유일하게 피치쓰만

19금으로 span class가 하나 더 있기 때문이었다 ^^
혹시 숙제 해설 코드에는 이거 없애는게 반영되어있나? 싶어서 코드 복사하고 실행해봤지만 마찬가지였다 ㅎㅎ
이게 너무나 거슬려서 해결을 해보려 했지만 증말 쉽지 않았다 ㅠ
ㅠㅠㅠㅠㅠㅠㅠㅠㅠㅠㅠㅠㅠㅠ
거의 1시간 가량 구글링하고 테스트해봐서 성공ㅠㅠㅠㅠㅠㅠㅠㅠㅠㅠㅠㅠ
3. 해결 방법
구글링을 해보았더니 function 하나를 알아낼 수 있었다.
바로 'descompose()'!!!
class의 아래에 있는 자식 태그를 골라내어서 지울 수 있는 메서드다.
descompose에 대한 설명이 잘 되어있는 블로그는 아래를 참조.
https://studyforus.com/innisfree/650714
[BeautifulSoup] 자식태그를 제거하기 - .decompose() & .extract() - Study For Us
안녕하세요?날씨가 쌀쌀해졌는데 다들 건강히 계시는지요? ^^이번 강좌에서는 BeautifulSoup에서 상대적으로 덜 사용되지만 유용한 두 메서드를 다뤄보고자 합니다.BeautifulSoup을 사용하다보면 자식
studyforus.com
이친구를 사용해서 없애보려 했지만 이 또한 쉽지 않았다.
왜냐하면 다른 곡들에는 span 태그가 없는데 피치쓰만 있으니까....
span class를 지워줘! 하면
여긴 span 없는데?ㅠ
와 같은 결과가 나왔다.

이를 해결하려면
"span이 있으면 > 지워주고 title 뽑아내
없으면 > 그냥 title 뽑아내"
와 같이 조건문을 이용해서 구분을 지어줘야한다.
if a.span is not None:
a.span.decompose()
title = song.select_one('a.title.ellipsis').text.strip()
else:
title = song.select_one('a.title.ellipsis').text.strip()이렇게 구분을 지어줘서
성공적인 결과를 볼 수 있었다 움하하
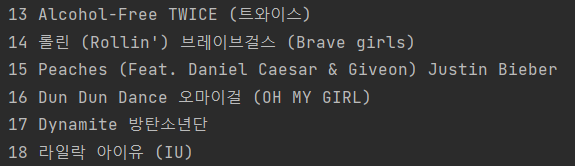
짜면서 알게 된 건, decompose는 단순히 "지워주는" 메서드라 굳이 따로 변수를 설정할 필요가 없는 것 같다.
뭔 말이냐면...
aa = a.span.decompose()
title = song.select_one('aa.title.ellipsis').text.strip()이렇게 a를 지운게 aa고, aa에서 title 뽑아내줘
하면 오류난다. 아마 내가 매트랩에 익숙해져 있어서 자꾸 변수 설정 하려는 것 같은데ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ
python에 익숙해지는 시간이 필요할 듯 하다....
4. 결론
사실 이것저것 막 해보면서 성공한 결과라 ㅠㅠ 원리를 잘 이해하고 짰는지는 모르겠다...
decompose 함수를 알고 나서도 거의 30분에서 1시간 정도 헤맨 듯 ㅠㅠ
class와 tag, 부모 자식 태그에 대한 이해도가 있어야 크롤링을 잘 할 수 있을 것 같다.
검색하다가 잘 정리해놓은 블로그가 있길래 또 따옴
코.알.못. 마케터도 크롤링하기#4. BeautifulSoup으로 정보가져오기
설명 영상을 게시글 아래에 추가하였습니다. (updated 2021.01.15) html 구조를 살펴보았다면, 이제는 실제...
blog.naver.com
시간을 엄청 많이 쓰긴 했지만 ㅠ_ㅠ
그래도 막상 성공하고나니 매우매우 뿌-듯 (●'◡'●)
기록하지 않고 넘어가기 아까워서 일지를 따로 써봤다.
'Development > Web development' 카테고리의 다른 글
| 웹개발 5주차 : 서버 업로드 (0) | 2022.02.11 |
|---|---|
| 웹개발 4주차 : POST & GET (0) | 2022.02.04 |
| 웹개발 3주차 : (2) DB 사용하기 (0) | 2022.02.04 |
| 웹개발 3주차 : (1) 파이썬 기본 문법과 크롤링 (0) | 2022.01.28 |
| 웹개발 번외편: 덕담 공유 페이지 만들기 (0) | 2022.01.27 |